 Блог Игоря Александровича Здесь вы найдете многое о заработке и сайтостроении
Блог Игоря Александровича Здесь вы найдете многое о заработке и сайтостроенииВсем доброго времени суток!
Я как всегда рад, что вы посещаете и читаете мой блог.
Сегодня, я хочу поговорить о дублях страниц. Как их найти, удалить и какой они могут принести вред вашему ресурсу.

Эта тема уже избитая, но по моему всегда будет актуальной.
По этому авторы и продолжают писать статьи на эту тему.
Что такое дубли страниц и откуда они берутся?
Дубль страницы, это еще одна копия вашей страницы. Так же есть не полное дублирование страницы и называется он частичным дубликатом.
В основном дубли страниц, генерируют сами движки, на WordPress это происходит мало чем на других движках.
Содержание статьи:
Больше всего дублей появляется на страницах, в рубриках, ну и архивах, а так же в комментариях.
А так же из-за ошибки самого блогера или смене адресов.
Чем грозит наличие дублей страниц, блогу
Дубли очень раздражают поисковые системы, особенно много дублей. Если Яндекс как — то сносно к этому относится, то Гугл этого не простит.
Два одинаковых текста, в глазах поисковиков теряют свою уникальность. А представьте если это происходит с половиною ваших статей. Это все для вашего блога, большая потеря позиций.
Так же вы теряете вес, который распределяется между оригинальными статьями и дублями.
Также идет потеря поведенческого фактора. Трафик будет идти и на дубли и на оригинальные статьи, то же самое будет происходить с оставленными ссылками на статьи.
Будут оставлять ссылку и на дубляж и на настоящую статью, этим вы будете терять естественные ссылочные.
Ну и самое главное, вы можете из-за дублей, попасть под фильтр Панда.
Как найти дубли страниц на блоге
Найти дубли страниц вашего блога, не проблема. Если они конечно присутствуют на вашем блоге.
Ну первое что вы можете сделать, это скопировать небольшой текст на вашем блоге и вбить его в поисковик, что бы проверить одинаковый текст, что в Гугле что в Яндексе.
А вообще есть специальные программы для этого, а так же сервисы.
Лично я использую программу Xenu Link Sleuth, ну и конечно же с помощью Яндекс вебмастера и Гугл вебмастера
Программа Xenu Link Sleuth
Скачиваем и активируем программу Xenu Link Sleuth

Заходим в программу и как показано на скрине выше, нажимаем на File в открывшейся вкладке, нажимаем на Check URL…
И нас перебрасывает на страничку, где нам нужно в верхней строке, внести адрес нашего блога и нажать кнопку окей.
Как показано на скрине ниже

После этого, начнется проверка вашего блога на ошибки и дубли страниц. Ошибки будут выделяться красным цветом, как показано на скрине ниже.
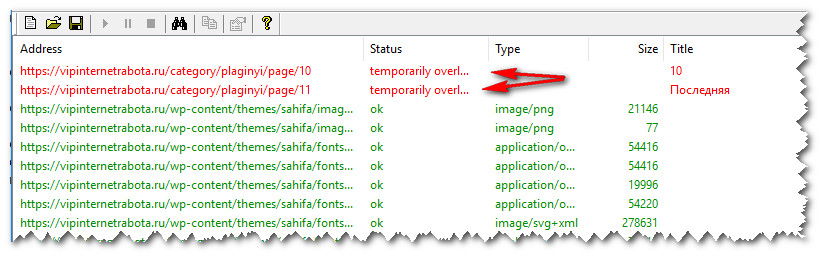
По окончании проверки, вас перебросит на страницу с отчетом. Там вы можете конкретно определить все дубли и ошибки.
Программа хороша тем, что находит и дубли и битые ссылки.
Об этом вы можете почитать в этой СТАТЬЕ
Сервис Вебмастер Google
Переходим в Google Webmasters
Далее в Панели инструментов, переходим во вкладку Вид в поиске и далее по ссылке Оптимизация HTML, как показано на скрине ниже.
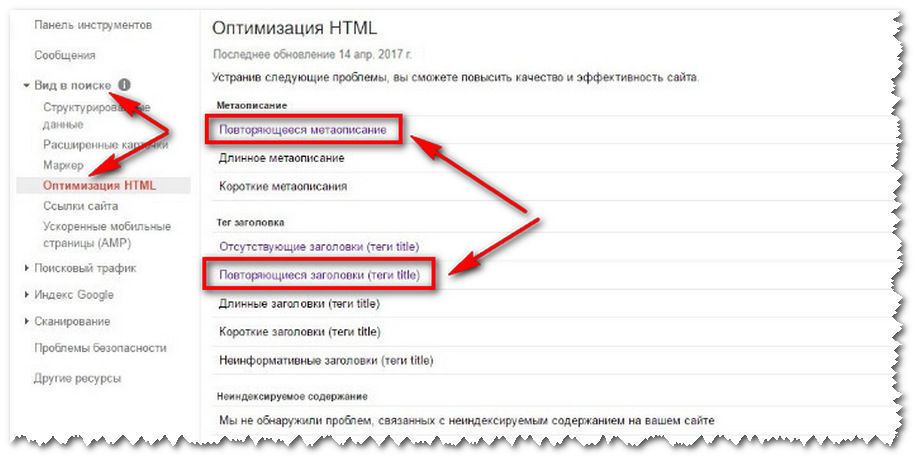
Вы видите на скрине выше, так же отмеченные пункты:
Повторяющееся метаописание и Повторяющиеся заголовки (теги title)
Здесь нам нужно проанализировать весь данный список страниц и где возможно легко выявить дубли.
Ну расписывать об поиске дублей, в Яндекс Вебмастере я не буду. Немного замороченней. По этому достаточно Вебмастера Гугл будет.
Убираем дубли страниц на блоге
Для начала, нам нужно пресечь источник дублей.
А это можно сделать, с помощью плагина All In One SEO Pack
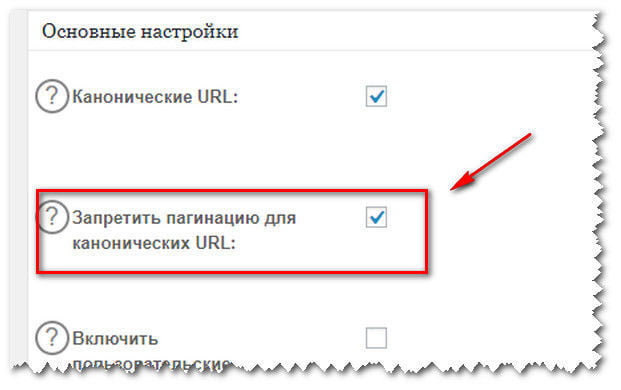
Заходим в настройки плагина и в Основных настройках и как показано на скрине ниже, в графе Запретить пагинацию для канонических URL, устанавливаем галочку.
А как установить и настроить плагин All In One SEO Pack, вы можете прочитать ЗДЕСЬ
Далее, нам нужно сделать запрет к индексации в robots.txt, некоторых разделов и страниц. Правда Google это не остановит и он продолжит индексировать
Так же нужно настроить 301 редирект, для переадресации поисковиков и читателей.
В Вебмастере Гугл, есть возможность отметить параметры и сообщить поисковику, что бы тот не индексировал страницу.
Это находится в разделе «Сканирование» — «Параметры URL»
Ну а теперь приступим к удалению ненужных нам ссылочных дублей
Заходим в Яндекс Вебмастер и как показано на срине ниже, переходим во вкладку Инструменты и нажимаем на ссылку Удалить URL
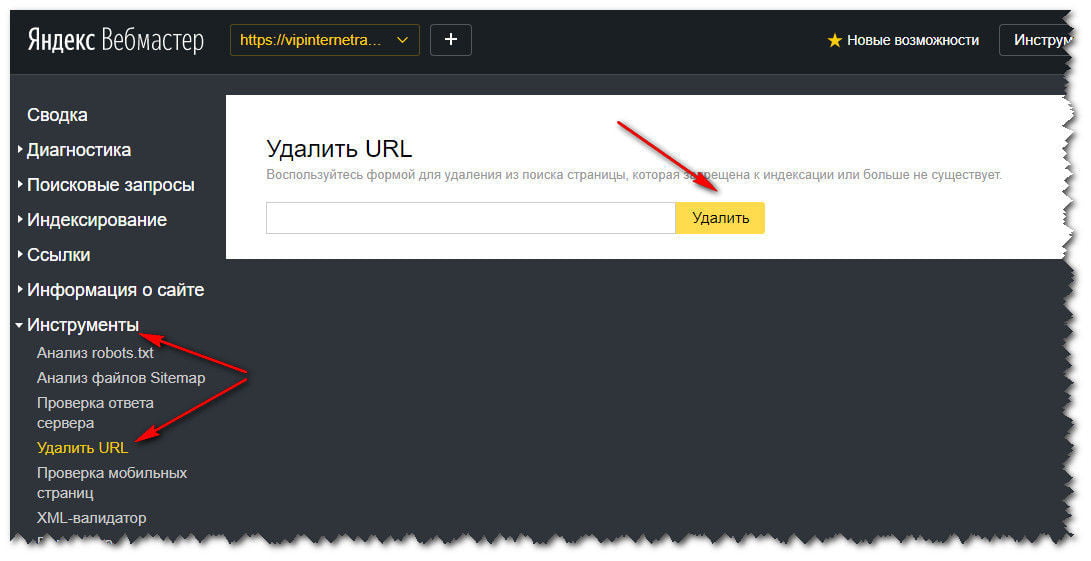
Здесь нам нужно будет внести не нужную ссылку и удалить ее. И так делаем с остальными ссылками, долго, но никуда не деться.
То же самое нам нужно сделать и в Вебмастере Гугл.
В панели инструментов, нам нужно зайти во вкладку Индекс Google и перейти по ссылке Удалить URL-адреса. Как показано на скрине ниже.
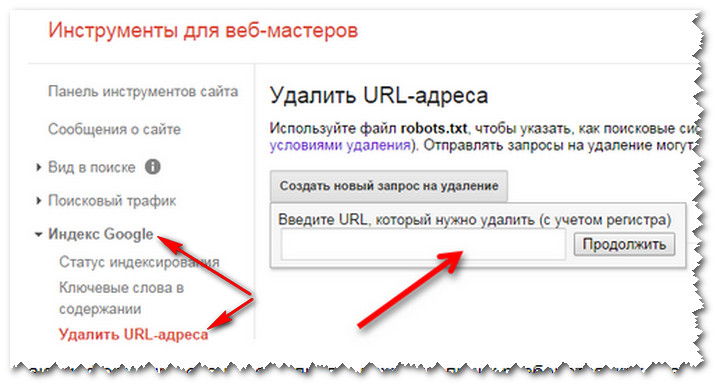
Ну и в графу, нам нужно вбить не нужную ссылку и удалить и так поступить со всеми дублями.
На этом я закругляюсь.
Думаю все ясно описал.
Будут вопросы, пишите, совместно разберемся))))
С Уважением, Игорь Александрович


Приветствую вас Игорь.
С удовольствием прочитал вашу статью о дублях.
Познавательно пишите, так держать
Добрый день Григорий!
Подтвердите ваш номер кошелька, я на него отправлю приз за первый комментарий.
Я смотрю номер остался тот же, приз выслал
Игорь, я не поняла как в отчете программы определить дубли страниц?Предположительно в первом столбце увидела, к примеру 4 ссылки на одну и ту же страницу. Скопировала их в один документ. При сравнении они все с разными «хвостиками». Первая ссылка оригинальная — заканчивается на htmlПрохожу в кабинет вебмастера гугл и далее как написано у Вас в статье и что? Гугл пишет мне что у меня все отлично и нет никаких повторяющихся метатегов.На этом бы ладноНо вот во вкладке индексация гугл — удалить урл адреса я так понимаю нужно прописать те самые ссылки с разными хвостиками. Правильно ли я поняла?Знаю, что дубли страниц у меня возможны и даже были проиндексированы. Так как наделала много ошибок распределяя статьи одновременно в несколько рубик, добавляла метки и даже плагин All in One SEO Pack у меня не был нормально настроен.Вот теперь навожу порядок. И зависла на удалении дубликатов.
И еще вопрос — почему сервисы анализа сайтов пишут что у меня проиндексировано гуглом от 0 до 196 страниц. А сам гугл показывает более точную цифру — 53. Кому верить?Блог молодой — на сайте около 45 должно быть.
Евгения здравствуйте!
Извините что не сразу ответил, ваш комментарий попал в папку спам и я его случайно заметил.
По определению и удалению дублей, вы правильно думаете, так и нужно делать.
Ну а на счет того, что у вас такой разбег между индексированными статьями, не переживайте.
Главное что Гугл правильно выдает статистику, а у сервисов присутствуют такие скачки, особенно для молодых блогов. Через какое то время, все встает на свои места.
Ну это мое мнение, что сервисы индексируют все в подряд, а потом отсеивать начинают.
Ну и конечно же и у вас все придет в норму
Если у меня есть сомнения насчет одной-двух страниц, то вручную так и прогоняю через поиск кусок текста) а если проект заходит, то быстрый способ аудитом в Serpstat прогнать. Хотя я брал Serpstat ради ссылок и анализа конкурентов, но грех не пользоваться аудитом, коль уже оплачено)